






XQC:
Well-Conditioned Optimization Accelerates Deep Reinforcement Learning
TL;DR: We introduce XQC; A well-conditioned critic architecture that achieves state-of-the-art sample efficiency on 70 continuous control tasks with 4.5× fewer parameters than SimbaV2.
Abstract
Sample efficiency is a central property of effective deep reinforcement learning algorithms. Recent work has improved this through added complexity, such as larger models, exotic network architectures, and more complex algorithms, which are typically motivated purely by empirical performance. We take a more principled approach by focusing on the optimization landscape of the critic network. Using the eigenspectrum and condition number of the critic's Hessian, we systematically investigate the impact of common architectural design decisions on training dynamics. Our analysis reveals that a novel combination of batch normalization (BN), weight normalization (WN), and a distributional cross-entropy (CE) loss produces condition numbers orders of magnitude smaller than baselines. This combination also naturally bounds gradient norms, a property critical for maintaining a stable effective learning rate under non-stationary targets and bootstrapping. Based on these insights, we introduce XQC: a well-motivated, sample-efficient deep actor-critic algorithm built upon soft actor-critic that embodies these optimization-aware principles. We achieve state-of-the-art sample efficiency across 55 proprioception and 15 vision-based continuous control tasks, all while using significantly fewer parameters than competing methods.
Results
We evaluate XQC on four challenging state-based continuous control benchmarks and pixel-based DeepMind Control:
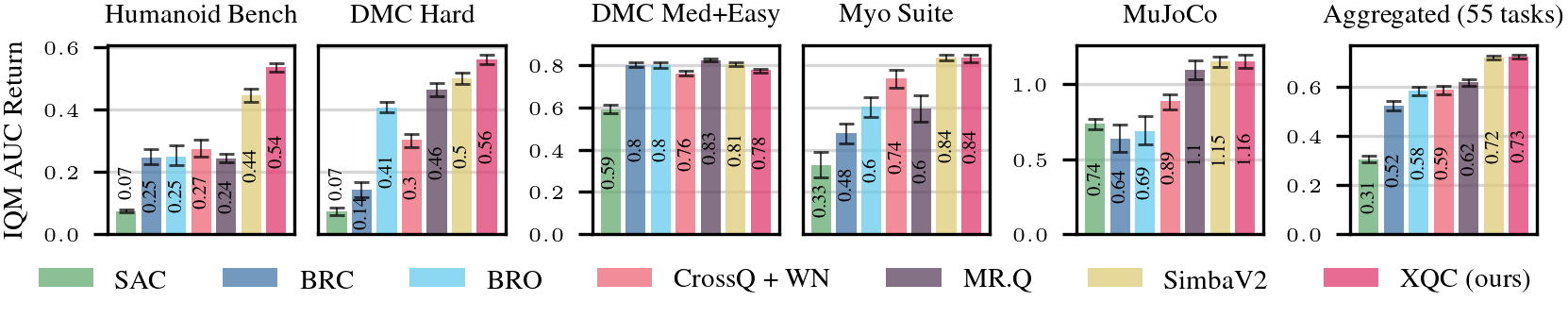
Proprioceptive RL (55 tasks)
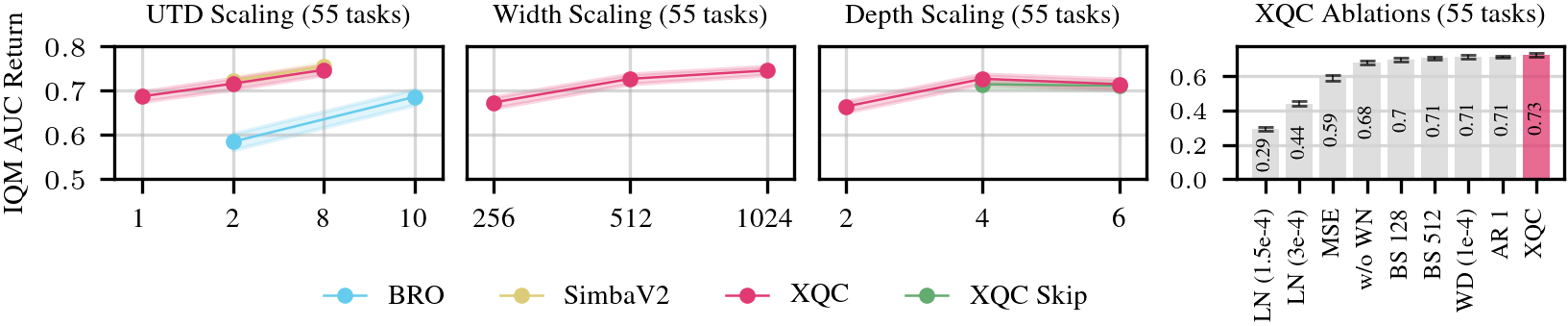
XQC outperforms SimbaV2, BRO, BRC, CrossQ+WN, and MR.Q across 55 proprioceptive tasks from HumanoidBench, DeepMind Control Suite, MyoSuite, and Mujoco — while using only ~2M parameters vs. SimbaV2's 9M.
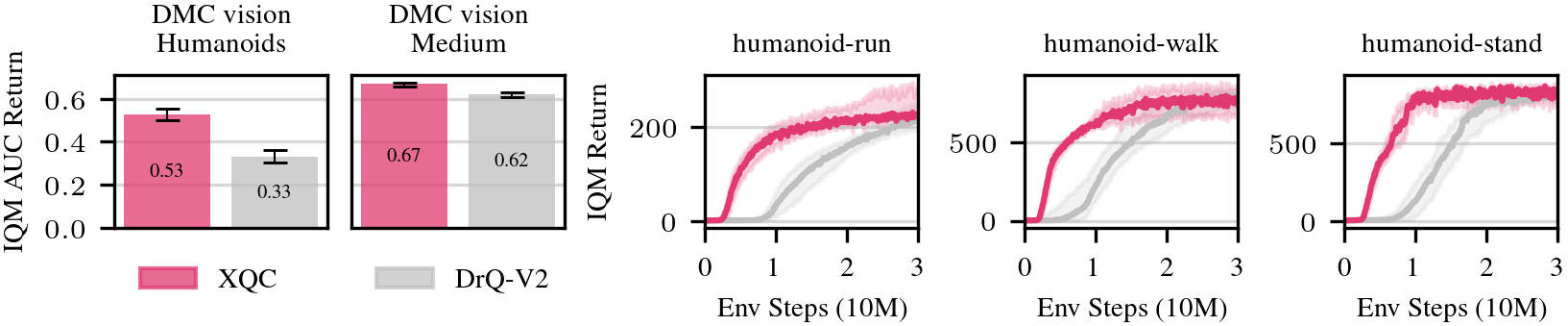
Pixel-based RL (15 tasks)
We demonstrate that XQC's sample efficiency scales from states to pixels. On 15 vision-based DMC tasks, XQC significantly improves upon DrQ-v2, especially on challenging humanoid environments.
Why Conditioning Matters
The condition number κ = λmax / λmin of the critic's Hessian is closely related to how fast gradient descent converges. High κ means the loss landscape is elongated — gradients oscillate instead of descending efficiently. We observe that better conditioning correlates with better RL performance.
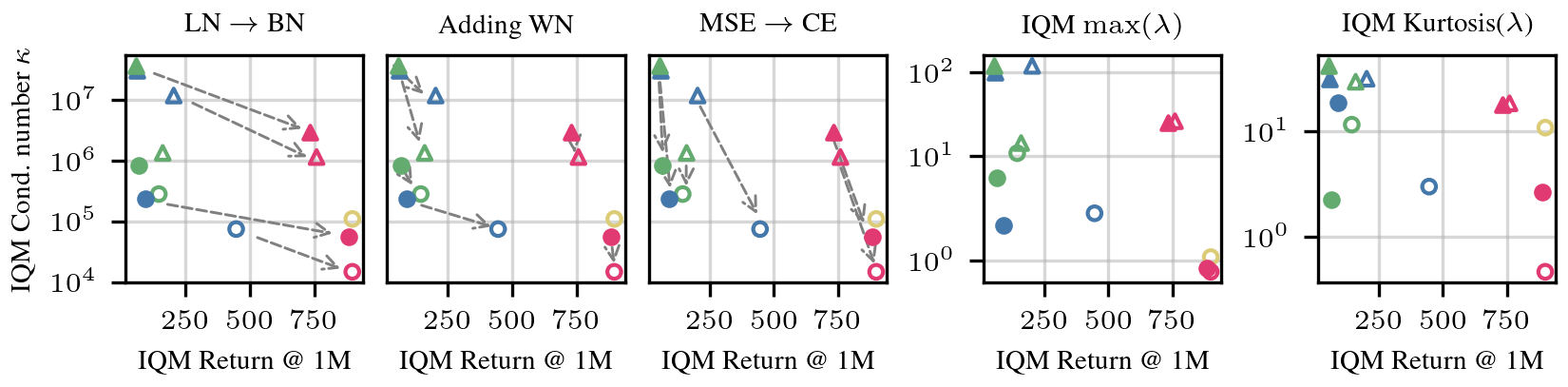
Architecture
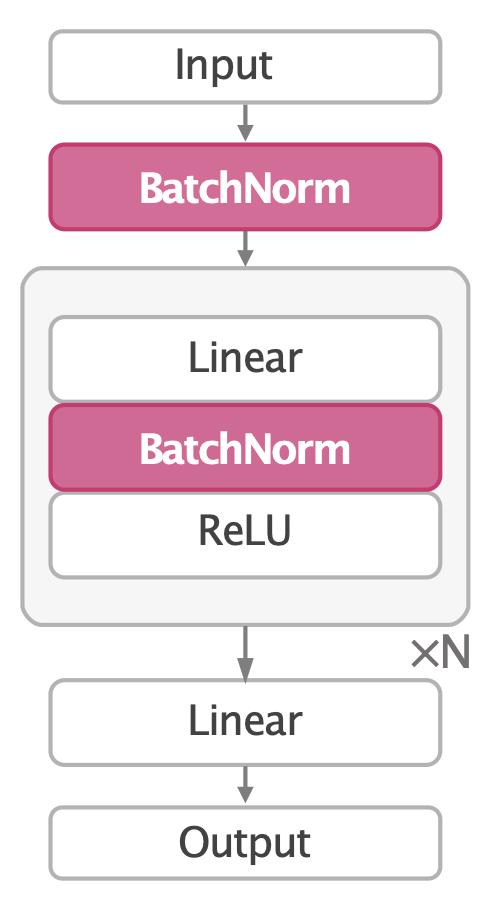
XQC uses a simple 4-layer MLP critic with batch normalization after each linear layer, weight normalization on all weights, and a distributional cross-entropy loss. No resets, no complex algorithmic tricks, no large networks.
These components address complementary pathologies in the optimization landscape: batch normalization controls the scale of activations and decouples weight magnitude from direction; weight normalization prevents unbounded parameter growth and stabilizes the effective learning rate; and the distributional cross-entropy loss replaces MSE with a classification objective over value bins, bounding gradient norms and further improving the Hessian spectrum. Together, they reduce the condition number by orders of magnitude.
Efficiency & Ablations
XQC is both parameter- and compute-efficient, scales with UTD ratio and network depth/width, and every component (BN, WN, CE loss) is necessary — removing any one degrades performance significantly.
Stable Training Dynamics
XQC maintains constant parameter norms, gradient norms, and effective learning rates throughout training — unlike ablations without WN or with MSE loss, which exhibit growing instabilities.

Further Reading
These papers represent our prior foundational work on leveraging Batch Normalization to scale and accelerate Deep Reinforcement Learning.
CrossQ
ICLR 2024 SpotlightIntroduced batch normalization for deep RL critics, achieving strong sample efficiency on simple tasks.
CrossQ+WN
NeurIPS 2025Identified weight growth as CrossQ's scaling bottleneck and fixed it with weight normalization, enabling reliable UTD scaling.
Gait in Eight
IROS 2025Demonstrated efficient on-robot quadruped locomotion learning, building on CrossQ-style sample efficiency.
Citation
@inproceedings{palenicek2026xqc,
title={XQC: Well-Conditioned Optimization Accelerates Deep Reinforcement Learning},
author={Palenicek, Daniel and Vogt, Florian and Watson, Joe and Posner, Ingmar and Peters, Jan},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}